1. Denormalize your data.
In Hive a good practice is to denormalize your data. With De-normalisation, the data is present in the same table so there is no need for any joins, hence the selects are very fast.
2. Execution Engine
Using your execution engine as tez or spark will optimize hive queries.
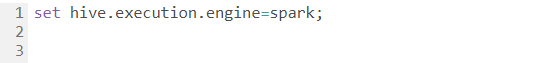
3. Usage of proper file format
Using proper file format based on your data will drastically optimize hive query performance. Generally ORC file format is best suitable for increasing your query performance. PARQUET format is another alternative. PARQUT format can be read by both Impala and Hive.

4. Optimize Hive Query by Vectorization
Vectorization improves operations like scans, aggregations, filters and joins, by performing them in batches of 1024 rows at once instead of single row each time. Operations are performed on the entire column vector, which improves the instruction pipelines and cache usage. This can optimize hive queries.

5. Cost based optimization
Optimize hive query’s logical and physical execution plan before submitting for final execution. These optimizations are not based on the cost of the query.
To collect statistics for the Hive query optimizer, set two parameters:

and then within Hive, enter the command:

There are a number of techniques available for improving the performance of Tableau visualizations and dashboards built from Hive. While Hadoop is a batch-oriented system, optimization hints listed above could reduce latency.
Visit our Tableau Dashboard Gallery.
